Parameter Efficient Self-Supervised Geospatial Domain Adaptation
Background
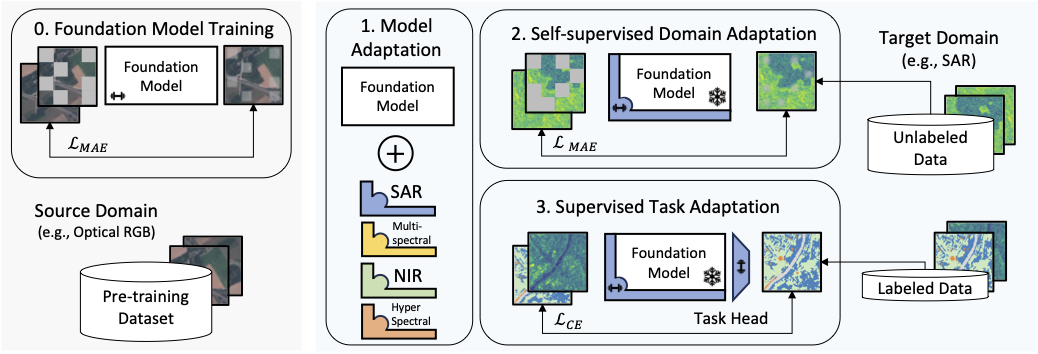
Pre-trained foundation models are widely used to solve computer vision problems, including with remote sensing imagery. The remote sensing field is characterized by widely varying imaging sensors and heterogeneous datasets. This limits the applicability of many visual foundation models, which are often pre-trained on a specific image modality. In this work, we present a self-supervised adaptation technique that makes it possible to efficiently adapt large, pre-trained foundation models to previously unseen imaging modalities.
Method
We propose a method that adapts existing foundation models to new modalities by introducing a small number of additional parameters and training the new parameters in self-supervised fashion on the target modality. These scaled low-rank (SLR) adapter parameters are added throughout the layers of the model to augment linear transforms in the transformer feed-forward blocks and QKV projections. Each adapter consists of learnable input and output scaling vectors si1,2 and low-rank matrices Wi1,2 that form a residual connection around the pre-trained linear transform Wi.
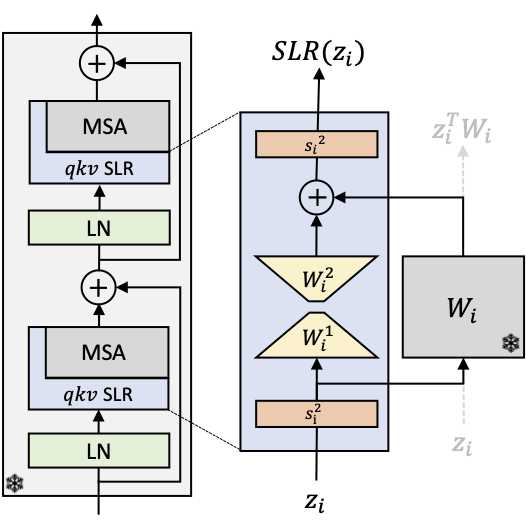
The adapters are trained with a masked-autoencoding approach on unlabeled data from target domain. For instance, an RGB foundation model can be adapted to SAR data by adding the adapters and training them on a SAR dataset. In the final step, we fine-tune the adapters along with a task-specific model head (e.g., segmentation or regression) on labeled dataset that could be much smaller.
Results
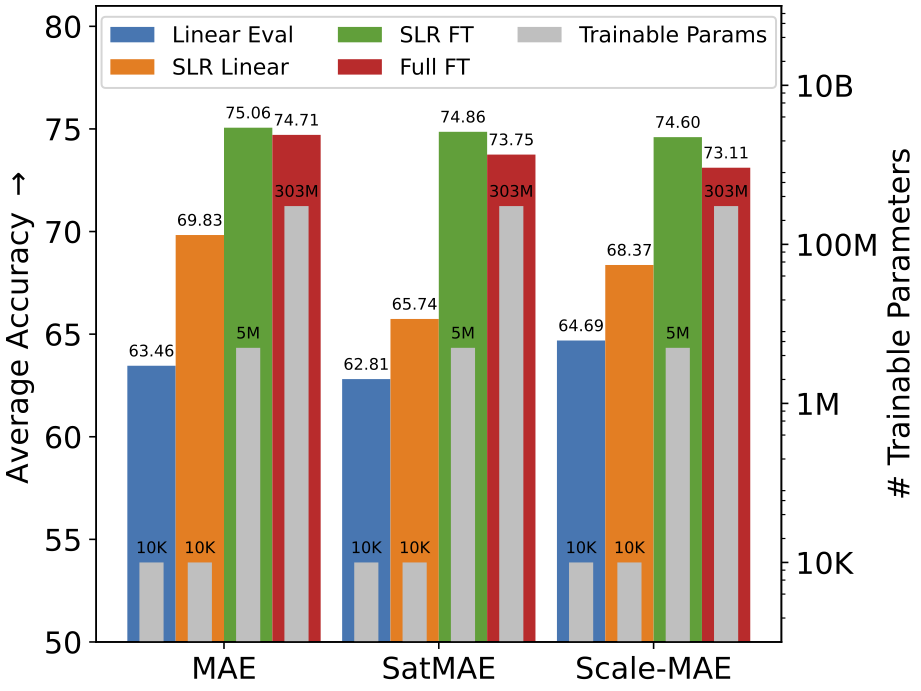
We test our method across different remote sensing datasets and visual foundation models. Average linear evaluation accuracy across eight classification and segmentation tasks significantly improves after incorporating and training SLR adapters for MAE, SatMAE and Scale-MAE foundation models. Fine-tuning of SLR adapters (1-2% of model parameters) results in performance that is on-par with supervised fine-tuning of the entire 300M ViT-L model.
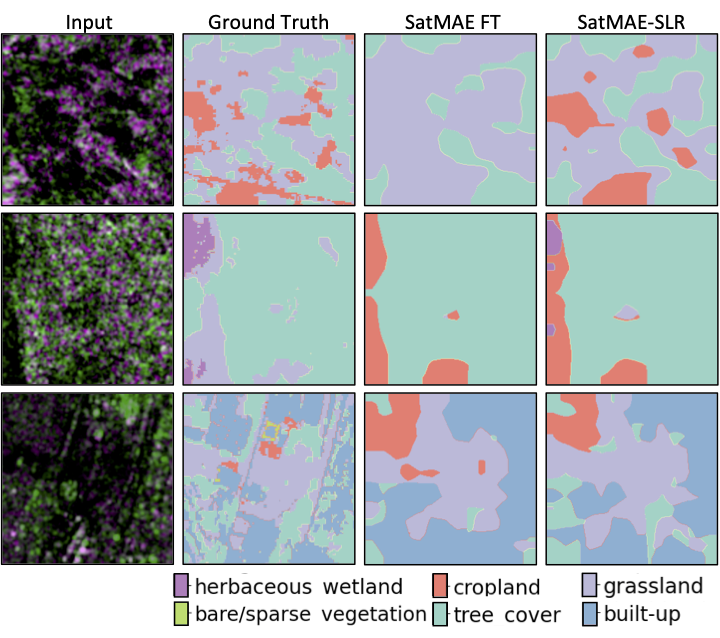
Qualitatively, we find that self-supervised adaptation improves the segmentation results on SAR data for foundation models that were trained on optical RGB data.
SLR Adapters
In our experiments, SLR adapters outperform parameter efficient fine-tuning methods such as BitFit, (IA)3, low-rank adaptation (LoRA), and tuning of normalizations (see Tab. 5 in the paper).
Additionally, SLR adapter facilitate few-shot learning through their scaling vectors, which can be adjusted effectively on very small datasets. We also find that self-supervised training of the adapters before supervised fine-tuning improves downstream performance, even without access to additional unlabeled data.
Conclusion
We present a new method to adapt foundation models to unseen modalities while avoiding costly fine-tuning. This enables supervised training of large models with a limited number of labeled samples and improves downstream performance on new modalities.