Self-supervised Vision Transformers for Land-cover Segmentation and Classification
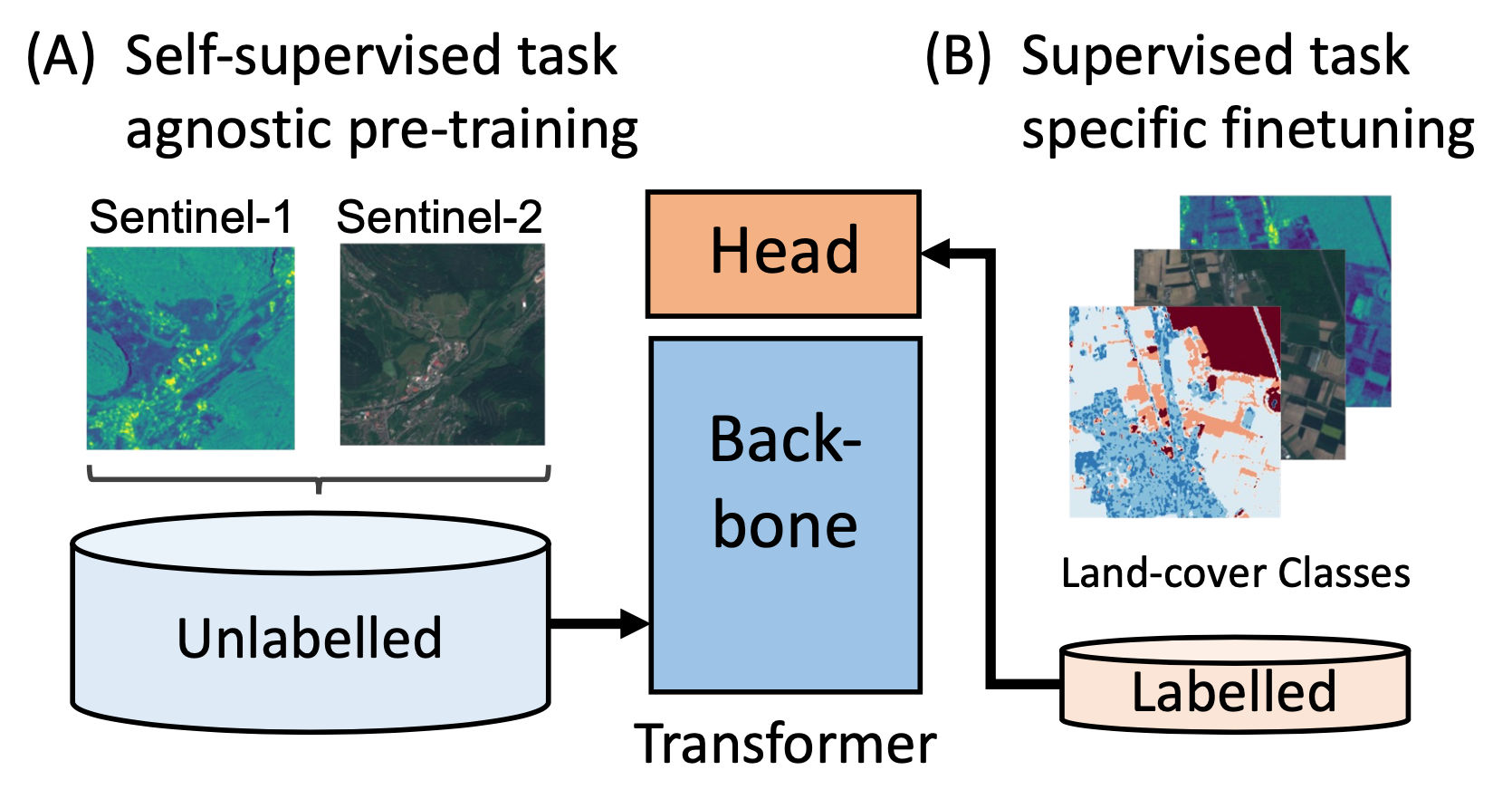
Transformer models have recently approached or even surpassed the performance of ConvNets on computer vision tasks like classification and segmentation. To a large degree, these successes have been enabled by the use of large-scale labelled image datasets for supervised pre-training. This poses a significant challenge for the adaption of vision Transformers to domains where datasets with millions of labelled samples are not available. In this work, we bridge the gap between ConvNets and Transformers for Earth observation by self-supervised pre-training on large-scale unlabelled remote sensing data. We show that self-supervised pre-training yields latent task-agnostic representations that can be utilized for both land cover classification and segmentation tasks, where they significantly outperform the fully supervised baselines. Additionally, we find that subsequent fine-tuning of Transformers for specific downstream tasks performs on-par with commonly used ConvNet architectures. An ablation study further illustrates that the labelled dataset size can be reduced to one-tenth after self-supervised pre-training while still maintaining the performance of the fully supervised approach.
Our proposed approach is trained in two stages. We propose to use large datasets of unlabelled remote sensing data for self-supervised pre-training of vision Transformers. After self-supervised training of the backbone, the model and task-specific head can be fine-tuned on much smaller labelled datasets for different downstream tasks. For pretraining, we utilize the SEN12MS (Schmitt et al., 2019) dataset, which contains co-located pairs of Sentinel-1 and Sentinel-2 patches, disregarding available labels; for fine-tuning, we utilize the GRSS Data Fusion 2020 dataset, which comes with high-fidelity LULC segmentation labels.

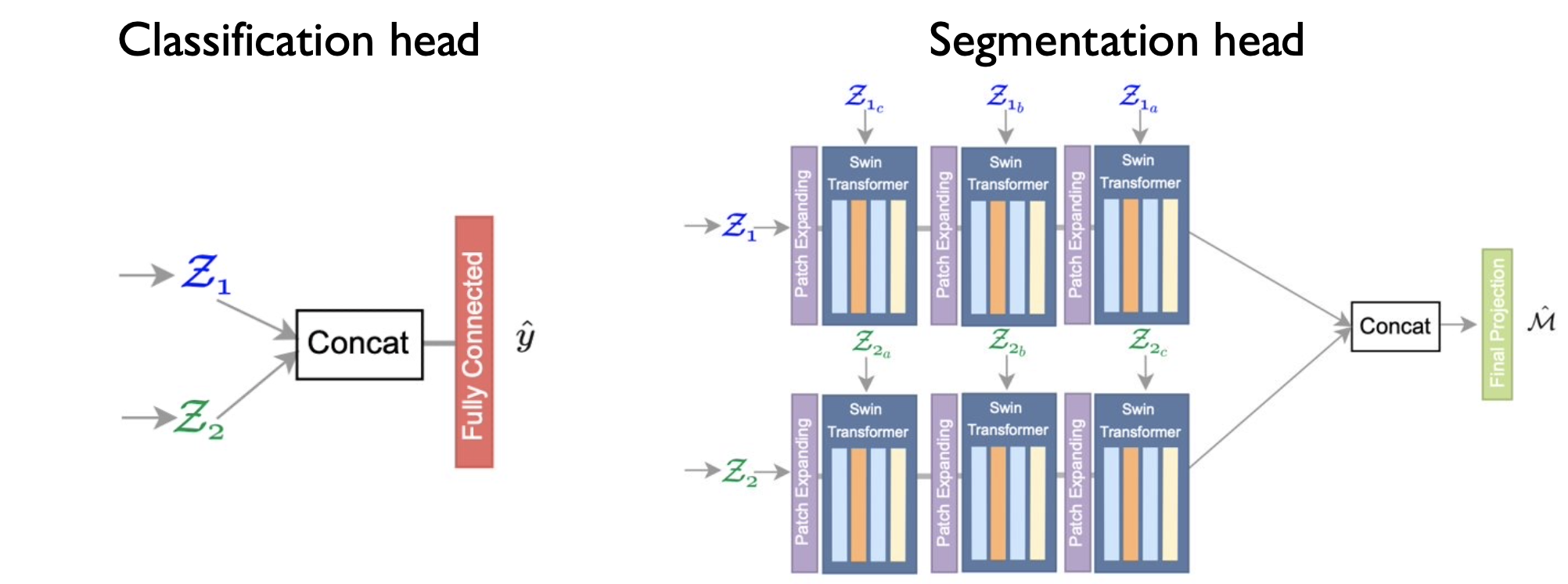
Our results show that latent representations derived through self-supervised pre-training are task agnostic and can be utilized for both land cover classification and segmentation. They also show that SSL in combination with vision Transformers or ConvNets can yield large performance gains (up to +30% over supervised baselines) across different downstream tasks when finetuned with labelled data.
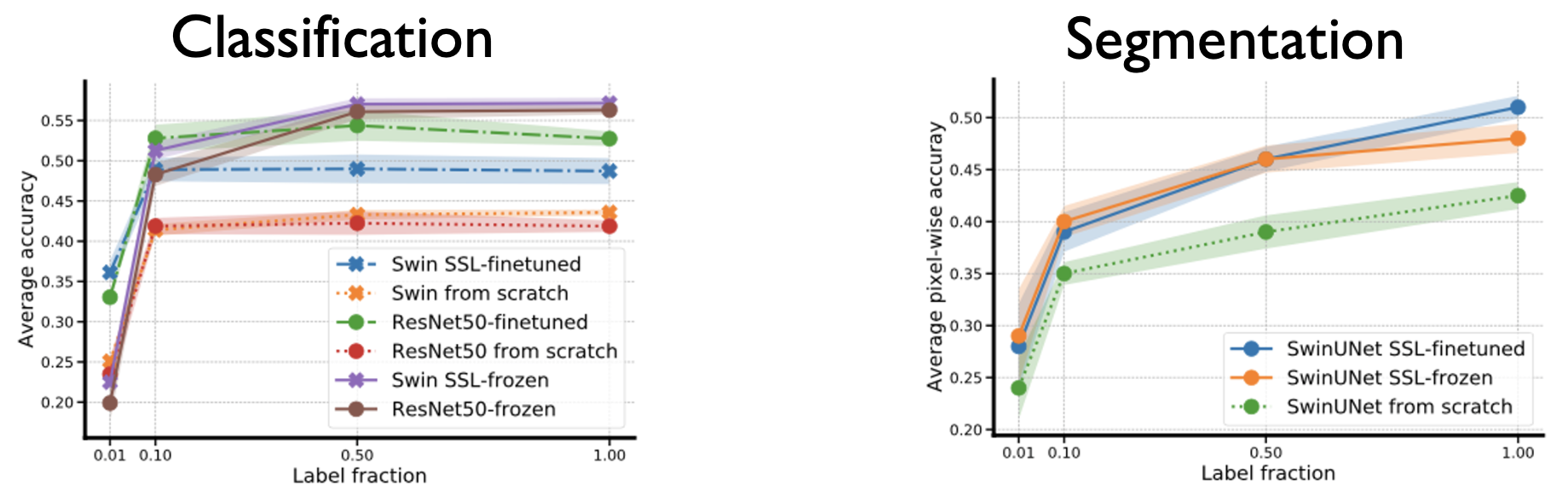
Moreover, we are able to show the efficiency of pre-training with our approach: with only 10% of the labelled data, all self-supervised models outperform the best supervised baselines trained on the entire dataset. The performance rapidly increases with the amount of available labelled training data for all models.
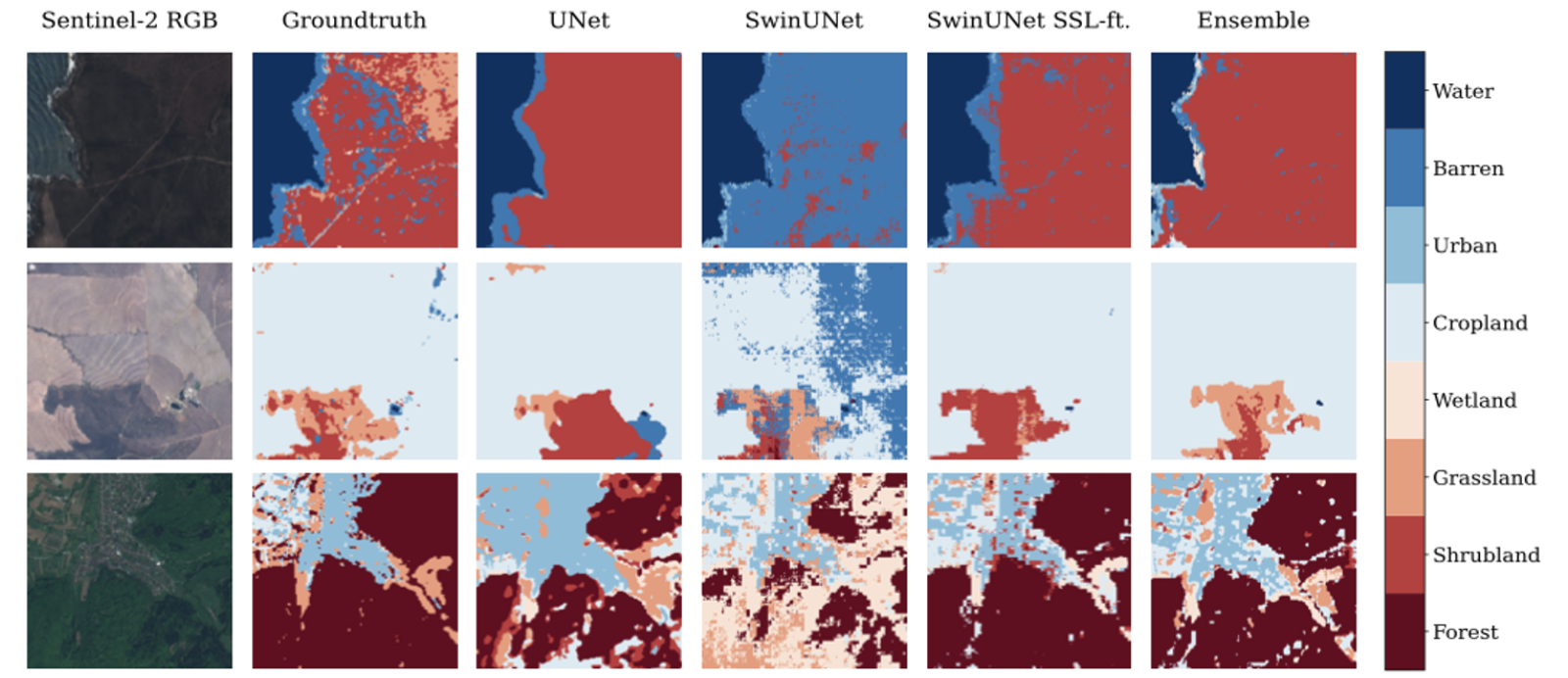
To conclude, our approach illustrates the utility of Transformer models for Earth observation applications without the need for large labelled datasets.
The results of this study have been presented at the CVPR 2022 Earthvision workshop in New Orleans, USA. This work received the Best Student Paper Award.