Self-Supervised Representation Learning on Neural Network Weights for Model Characteristic Prediction
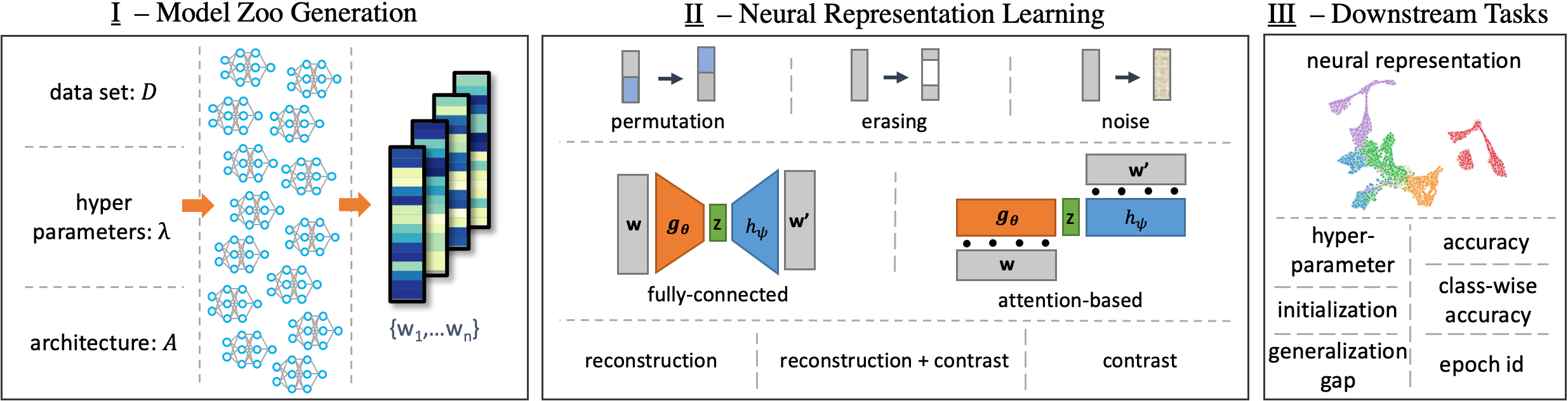
Self-Supervised Learning (SSL) has been shown to learn useful and information-preserving representations. Neural Networks (NNs) are widely applied, yet their weight space is still not fully understood. Therefore, we propose to use SSL to learn neural representations of the weights of populations of NNs. To that end, we introduce domain specific data augmentations and an adapted attention architecture. Our empirical evaluation demonstrates that self-supervised representation learning in this domain is able to recover diverse NN model characteristics. Further, we show that the proposed learned representations outperform prior work for predicting hyper-parameters, test accuracy, and generalization gap as well as transfer to out-of-distribution settings.
Background
Within Neural Network populations, not all model training is successful, i.e., some overfit and others generalize. This may be due to the non-convexity of the loss surface during optimization, the high dimensionality of the optimization space, or the sensitivity to hyperparameters, which causes models to converge to different regions in weight space. What is still not yet fully understood, is how different regions in weight space are related to model characteristics.
Previous work investigating NN models often relies on data to compute the mapping of NN models, compares pairs of models or directly predicts single characteristics. In contrast, our idea is to investigate populations of models in representation space to identify model characteristics.
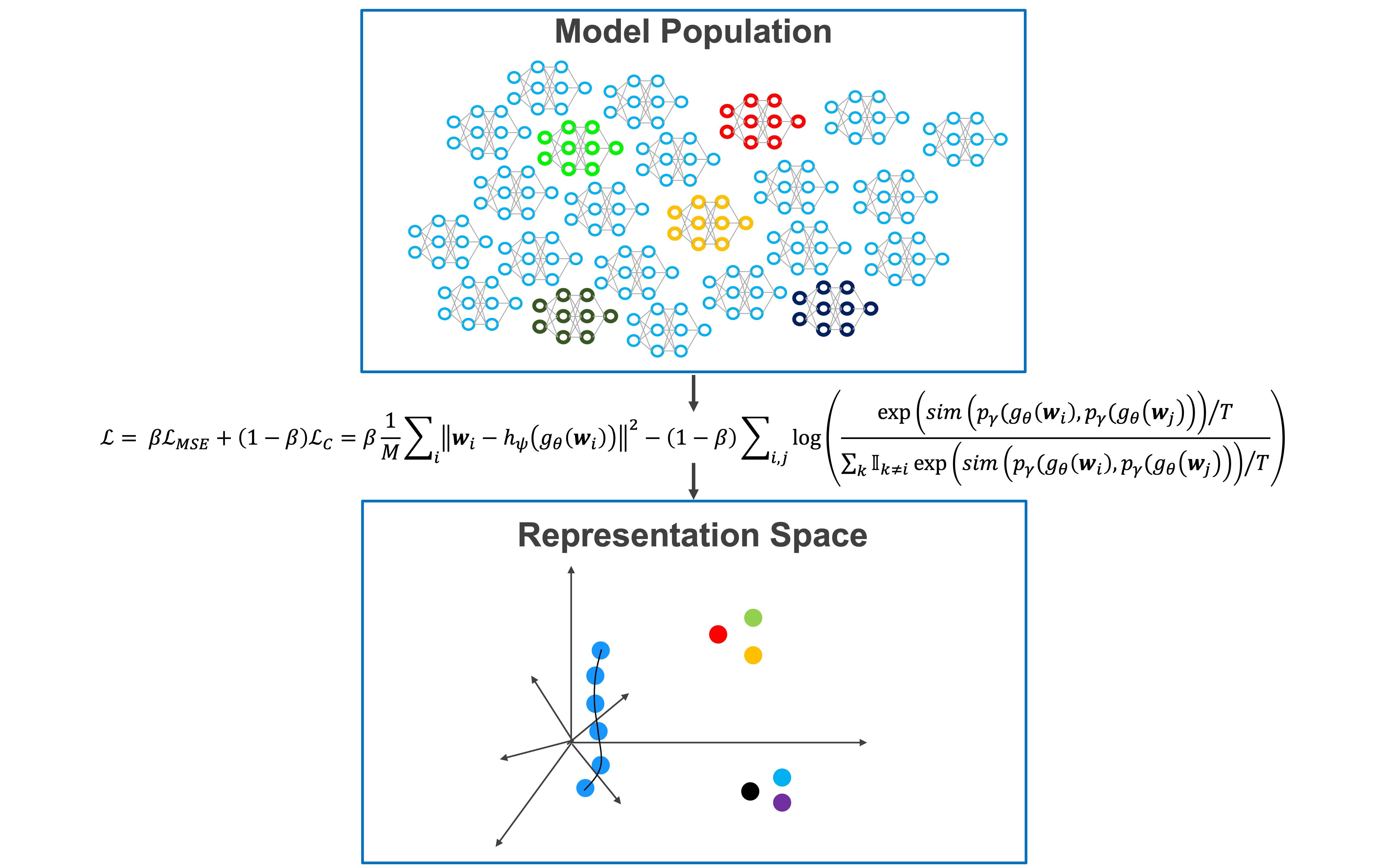
Our goal is to learn task-agnostic, rich representations from populations of NN models which are able to reveal a diverse range of model characteristics.
Approach
Self-Supervised Learning is able to reveal latent structure in complex data without the need of labels. We propose a novel approach to apply SSL to learn representations of the weights of NN populations, as outlined in the scheme above. We introduce three augmentation methods for NN weights. In particular, the permutation augmentation leverages symmetries of the NN weight space to create samples that are equivariant in forward and backward pass. Empirically, we find the permutation augmentation necessary to learn generalizing representations. Further, we propose an attention-based architecture, which understands NN models as sequences of components, i.e., sequences of neurons. As SSL tasks, we evaluate reconstruction, a contrastive loss, and a combination of both. As evaluation, we predict model characteristics, such as accuracy, epoch, or hyperparamters, from the learned representations.
Results
We evaluate our approach on eleven different model zoos. Across all of them, we find that neural representations can be learned and reveal the characteristics of the model zoos. We show that neural representations have high utility predicting hyper-parameters, test accuracy, and generalization gap, as the Table below shows. This empirically confirms our hypothesis on meaningful structures formed by NN populations. Furthermore, neural representations outperform the state-of-the-art for model characteristic prediction and generalize to out-of-distribution zoos.
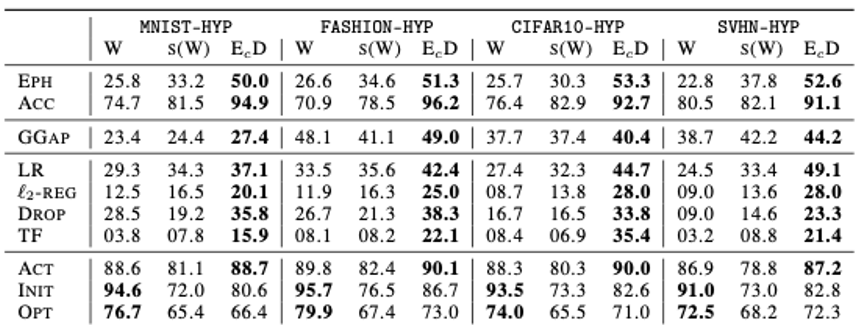
For our experiments, we use publicly available NN model zoos and generate seven new model zoos with diverse generating factors. Our ablation study confirms that the various factors for generating a population of trained NNs play a vital role in how and which properties are recoverable for trained NNs. In addition, the relation between generating factors and model zoo diversity reveals that seed variation for the trained NNs in the zoos is beneficial.