Deep Learning in Assurance & Audit
The developments in information technology, such as modern database technologies, the advances ofend-to-end data communication and cloud computing, led to a multitude of efforts by organizations to digitize their business processes progressively. This digital transformation resulted, among others,in the advent of modern “Enterprise Resource Planning (ERP)” systems and fundamentally changed the nature and source of audit evidence. Nowadays, such systems, administrate a wide variety of financial accounting relevant processes, controls and reports built around relational database systems. As a result, ERP systems steadily collect vast quantities of audit relevant information at a granular level.
The objective of this research endevour is the investigation of the applicability of deep learning as a novel analytical audit procedure in the context of financial statement audits. Thereby our research examines a new avenue of how auditors can use the advantages that deep-learning promises and are already applicable in other domains. In detail, we aim to investigate the following directions of research:
Representation Learning
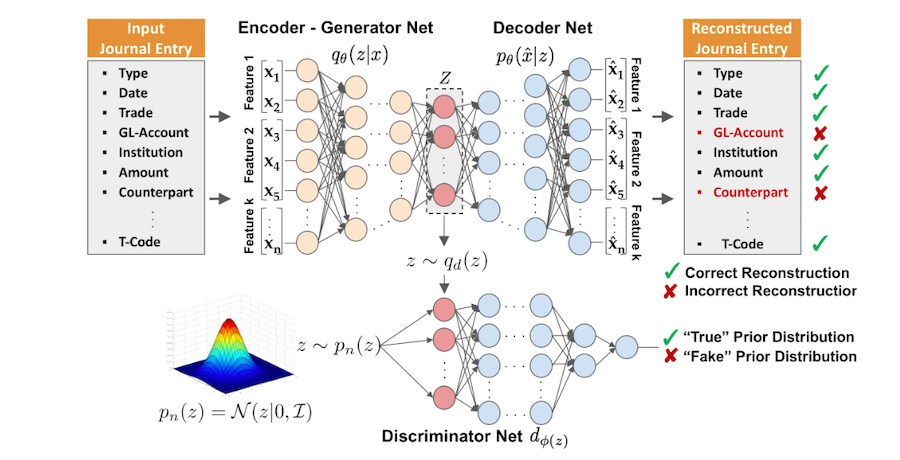
Motivation: “Representation Learning” refers to the learning of data representations that correspond to more abstract, and ultimately more useful, information for a given downstream task (Ridgeway, 2016). The objective of “unsupervised” representation learning is to learn representations that expose semantic features as disentangled generative factors without human supervision (Chen et al., 2016). For example, for a dataset of faces, a useful disentangled representation may allocate a separate set of dimensions for each of the following attributes: facial expression, eye colour, hairstyle, presence or absence of eyeglasses. Formally, a disentangled representation can be defined as one where “single latent units are sensitive to changes in single generative factors while being relatively invariant to changes in other factors” (Bengio et al., 2016).
Application in Assurance & Audit: Accounting data arises from the interaction of a complex set of generative factors. Currently, the performance of “Computer Assisted Audit Techniques (CAATs)” significantly depends on the choice of data representations, also referred to as “features”, of the accounting data’s inherent generative factors. The handcrafted engineering of such representations is a way to take advantage of a human auditor’s ingenuity and prior knowledge. However, the inability of CAATs to extract and disentangle such discriminative information themselves highlights a disadvantage. Furthermore, the handcrafting of such representations often results in a labour intensive effort. Ultimately, it may introduce an undesired bias into the learned deep model. Therefore, the learning of such representation directly “end-to-end” and suitable for a given audit task defines a next evolutionary step in expanding the capabilities of CAATs.
Research Questions: The research of the unsupervised learning of effective representations of accounting data without human supervision for downstream audit tasks is still in its infancy. Therefore, in this context, we investigate the following research questions regarding representation learning of accounting data:
-
Question 1: Can deep learning techniques be applied to learn disentangled representations of the latent generative factors of variation evident in accounting data?
-
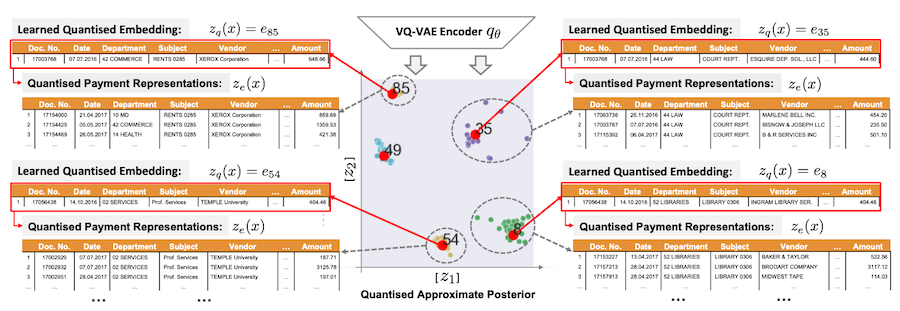
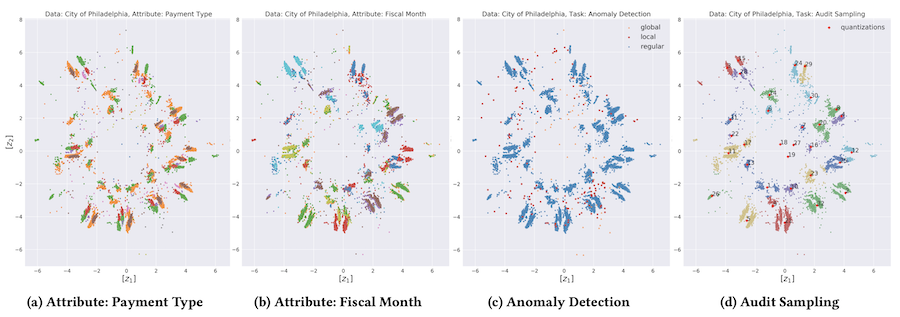
Question 2: Can such learned representations be useful for downstream audit tasks, such as (i) the selection of representative audit samples or (ii) the detection of accounting irregularities?
Our Publications:
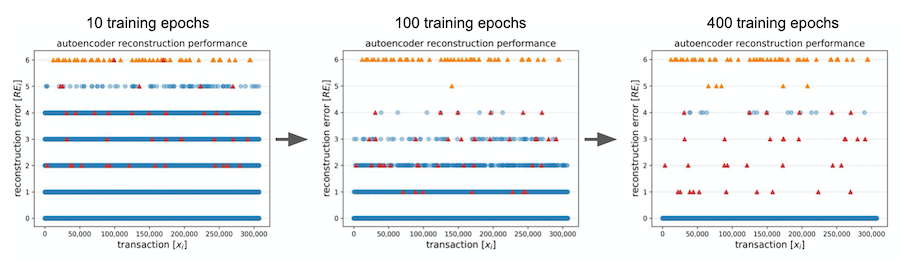
M. Schreyer, T. Sattarov, D. Borth, A. Dengel, and B. Reimer, “Detection of Anomalies in Large Scale Accounting Data using Deep Autoencoder Networks”, NVIDIA’s GPU Technology Conference, San José, USA, 2017. [paper][code]
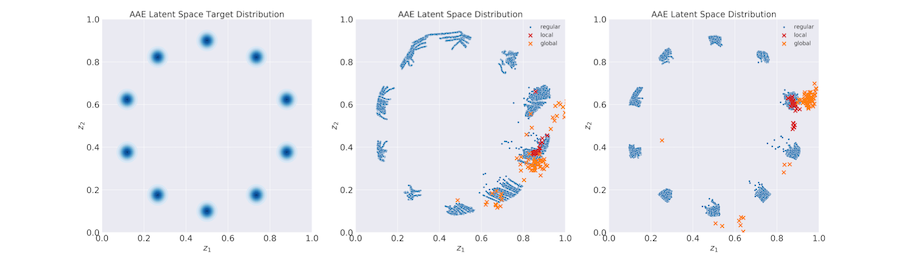
M. Schreyer, T. Sattarov, C. Schulze, B. Reimer, and D. Borth, “Detection of Accounting Anomalies in the Latent Space using Adversarial Autoencoder Networks”, ACM KDD Workshop on Anomaly Detection in Finance, Anchorage, USA, 2019. [paper][code]
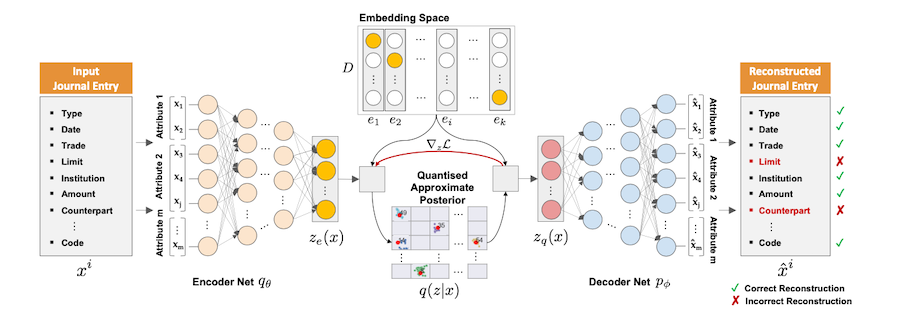
M. Schreyer, T. Sattarov, A. Gierbl, B. Reimer, and D. Borth, “Learning Sampling in Financial Statement Audits using Vector Quantised Autoencoder Neural Networks”, ACM International Conference on AI in Finance, New York, USA, 2020. [paper][slides]
M. Schreyer, T. Sattarov, and D. Borth, “Multi-view Contrastive Self-Supervised Learning of Accounting Data Representations for Downstream Audit Tasks”, ACM International Conference on AI in Finance, London, UK, 2021. [paper]
Adversarial Learning
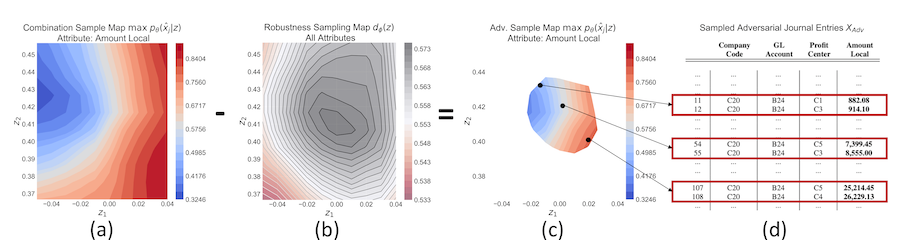
Motivation: Intriguing discoveries in deep learning research revealed that a variety of machine learning models, even simple regression models, are vulnerable and exhibit “intrinsic blind spots”. In computer vision, (Szegedy et al., 2013) and (Goodfellow et al., 2014) were among the first who demonstrated that small perturbations added to an image, resulting in misclassifications by machine learning models. Such perturbations, referred to as “adversarial examples”, pose a threat to a variety of real-world applications e.g. autonomous driving (Eykholt et al., 2017), speech recognition (Alzantot et al., 2018), text generation (Chen et al., 2018) or reinforcement learning (Huang et al., 2018). “Adversarial attacks” are deliberately designed to exploit such vulnerabilities and cause a machine learning model to make a mistake.
Application in Assurance & Audit: The research of the potential impact of adversarial attacks and deepfakes in finance and accounting is still in an early stage. In the past, the creation of convincing deepfakes used to be reserved for a small group of highly trained professionals. With the advent of deep adversarial learning, it became broadly accessible within reach of almost any individual with a computer. As a result, obtaining an understanding of how adversarial deep learning techniques can be maliciously misused to attack an audit is of vital relevance. This observation holds in particular for attack vectors designed to obfuscate fraudulent activities by the replacement or augmentation of accounting irregularities, e.g. to cover up the circumvention of an invoice approval border in the procure to pay process. Finally, as of now, it also seems unclear if state-of-the-art CAATs are able to detect such attacks.
Research Questions: The research of the potential impact of adversarial learning and corresponding attacks in the finance and particular accounting domain is still in an early stage. Therefore, in this context, we investigate the following research questions regarding the vulnerability of financial audits and associated analytical audit procedures by “adversarial examples” and “deepfakes”:
-
Question 1: Can adversarial deep learning techniques be misused to generate “accounting fakes” that misguide auditors in the professional judgement on particular audit evidence?
-
Question 2: Can adversarial deep learning techniques be misused to learn “attack vectors” that misguide state-of-the-art CAATs on particular factual audit evidence?
Our Publications:
M. Schreyer, T. Sattarov, B. Reimer, and D. Borth, “Adversarial Learning of Deepfakes in Accounting”, NeurIPS 2019 Workshop on Robust AI in Financial Services: Data, Fairness, Explainability, Trustworthiness, and Privacy, Vancouver, Canada, 2019. [paper][talk][slides]
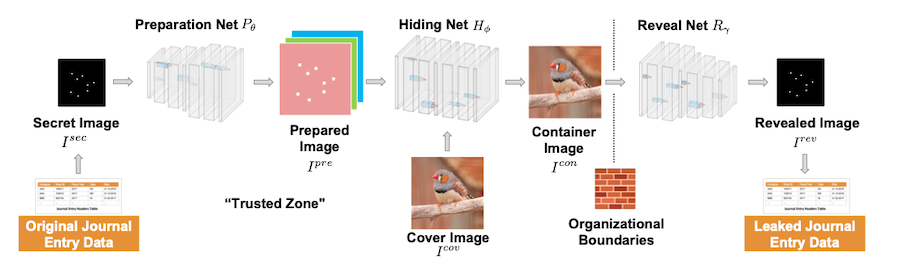
M. Schreyer, C. Schulze, and D. Borth, “Leaking Sensitive Financial Accounting Data in Plain Sight using Deep Autoencoder Neural Networks”, AAAI 2021 Workshop on Knowledge Discovery from Unstructured Data in Financial Services, Virtual, 2021. [paper][slides]